This article introduces how I tackle occlusion errors in depth completion caused by stereo calibration without requiring raw sparse depth data.

Fig. 1, Occlusion errors removing in ToF depth maps. Given an color image and a sparse depth (first column), we stack those images to see the impact of occlusion errors caused by dual calibration (top of second column), and masked sparse depth (bottom of second column) by estimated confidence mask. We shown the SOTA depth completion model EMDC [2] benefits from our method (third column).
In this article, we propose a method for addressing occlusion errors in depth completion caused by stereo calibration. Our unsupervised training procedure, not relying on any ground-truth data, combines pseudo labels generation and confidence estimation to reduce the amount of error introduced into the depth map for depth completion. Occlusion errors in depth completion refer to situations where the model incorrectly estimates the depth of an object that is partially or fully obscured by another object. This can happen when the model is not able to fully understand the context of the scene and the relationships between different objects. Occlusion errors can lead to inaccuracies in the final depth map and can negatively impact the performance of downstream tasks that use the depth information, such as depth completion, object detection and tracking. As shown in Fig.1, our experimental results demonstrate the effectiveness of our approach in reducing occlusion errors and retaining the overall accuracy of the depth map.
The goal of depth completion is to complete the depth channel of an RGB-D image. In order to establish a precise relationship between two camera coordinates, stereo calibration estimate the intrinsic and extrinsic parameters of a pair of cameras to establish accurate correspondence between their image coordinates. This relationship is crucial for many applications in computer vision. However, stereo calibration usually induces negative effects such as occlusion errors, which typically arise when certain parts of the scene or objects are obstructed or hidden from one of the cameras. There are several ways to address occlusion errors caused by stereo calibration in depth completion: 1) Multi-view depth completion, by using multiple views of the same scene, the model can better understand the context of the scene and the relationships between objects, which can help to reduce occlusion errors; 2) Attention-based models are able to focus on specific parts of the input, which can help the model to better understand the relationships between objects and reduce occlusion errors; 3) Adversarial training can be used to improve the robustness of the model to occlusion by training it to generate realistic depth maps even when there are occlusions present in the scene.
There have been several prior works on addressing occlusion errors. [1] estimate confidence in LiDAR depth maps in an unsupervised manner and predict the uncertainty of the depth values. This method requests exist dataset which provide raw depth map with occlusion errors and expensive annotations such as KITTI [3]. However, there no exist Time of Flight(ToF) dataset that satisfy this assumptions. It’s worth noting that no single method is likely to be a complete solution to the occlusion problem in depth completion. Often, a combination of methods is used to address occlusion errors in depth completion.

Fig. 2, The impact of occlusion errors leads worse results of the SOTA depth completion method EMDC [2].
The impact of occlusion errors shown in Fig.2.
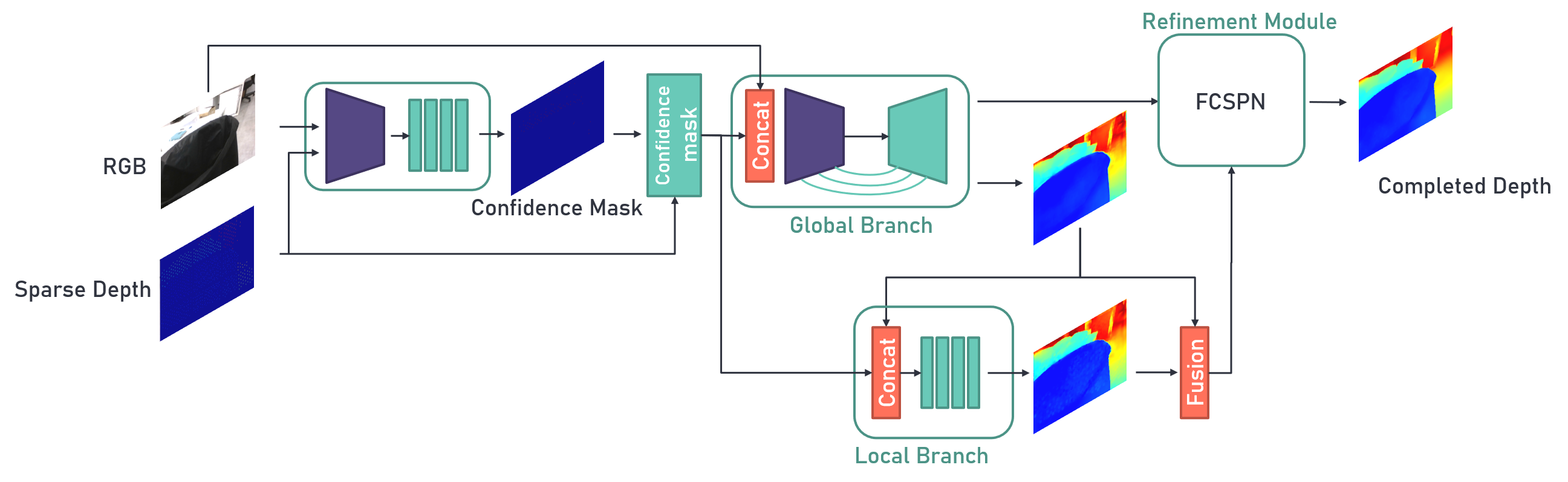
Fig. 3, Overall pipeline of proposed method. A pair of color and sparse images is first concatenated and sent to a feature extractor to get the features $F$, which is used to generate spacial-encoded features at different resolutions. The features $F$ then be up-sampled and feeds into a MLP to estimates confidence mask. Color and masked sparse images are then used to two-branch global and local network. Finally, a popular refinement technique FCSPN is introduced for depth refinement to obtain completed depth.
Given an RGB image $i$ and depth image $d_{gth}$, We firstly generate sparse depth $d_s$ from $d_{gth}$. Stereo-Aware Augmentation aims to generate pseudo sparse depth with occlusion errors $\hat{d}$ to mimic process of stereo calibration. Subsequently, we feed $i$ and $\hat{d}$ into Confidence Estimation Module to estimate $d^{*}$ and corresponding uncertainty $\sigma$. Eventually, during inference, occlusion errors of sparse depth induced from dual-calibration will be removed by Confidence Estimation Module. Overall method shown in Fig.3. Note that our method do not request any dataset which provide raw depth map with occlusion errors.

Fig. 4, Stereo-Aware Augmentation.
Stereo-Aware Augmentation As shown in Fig.4, to generate pseudo sparse depth with occlusion errors $\hat{d}$, we warp depth image $d_{gth}$ with an 3D projection with proper extrinsic parameters. More specifically, 1) project ground truth depth to 3D, 2) rotation is performed around the x or y axis, it maps depth points from original position to specific position, then 2) project back to 2D and extract mask to get occlusion points, 3) shifting occlusion points and 4) obtaining masked original sparse depth points. Note that available intrinsic matrix and well-select extrinsic matrix are requested.
Confidence Estimation Module The goal of a confidence estimation module is to provide an estimate of the reliability or uncertainty of sparse depth associated with the input RGB image. In this article, we introduce an additional module into the existing depth completion network to estimate the confidence scores. This module can be trained using following loss functions that encourage retaining reliable sparse depth points. Inspired by [1], We model the confidence of pseudo sparse depth with occlusion errors $\hat{d}$ assuming a Gaussian distribution centred in the sparse depth $d^*$ with variance $\sigma^2$, the latter encoding the depth uncertainty. Then train the module with sparse depth $d_s$ to regress $\sigma$ by minimizing the negative log-likelihood of the distribution.
Depth Completion Model Confidence Estimation Module then be cascaded with the any depth completion model such as EMDC [2], to obtain improved sparse depth and achieve superior depth completion results.

Fig. 5, Qualitative result of our method. EMDC tends to make mistakes on the region of occlusion errors. In contrast, our method learns confidence mask to filter out occlusion errors and produces accurate and sharp object boundaries.
As shown in Fig.5
The depth maps generated by sensors must often be coupled with an RGB camera to understand the framed scene semantically. Unfortunately, this process, coupled with the intrinsic issues affecting all the depth sensors, yields noise and gross outliers in the final output. We figure out that model suffers from occlusions error which caused by 1) applying spatial filter, 2) erroneous measurements and 3) stereo calibration. To tackle this, we propose the Stereo-Aware Augmentation, an effective supervised framework aimed at explicitly addressing this issue by learning to estimate the confidence of the sparse depth map and thus allowing for filtering out the outliers.
[1] Conti, Andrea, et al. Unsupervised confidence for LiDAR depth maps and applications. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022.
[2] Dewang Hou, et al. Learning an Efficient Multimodal Depth Completion Model. ECCV Workshop, 2022.
[3] Andreas Geiger, et al. Vision meets Robotics: The KITTI Dataset. International Journal of Robotics Research (IJRR), 2013.
 You-Feng Wu
You-Feng Wu