This article introduces how I designed Node Attention Module from scratch under certain conditions. Our goal is to provide a plug-and-play module to extract sub-actions upon any existing action detection approaches.
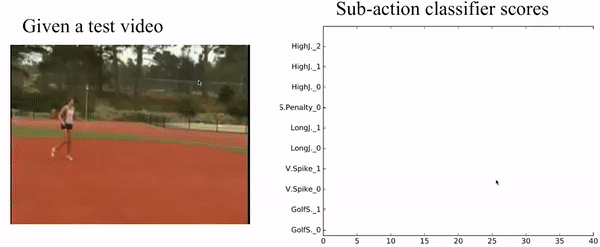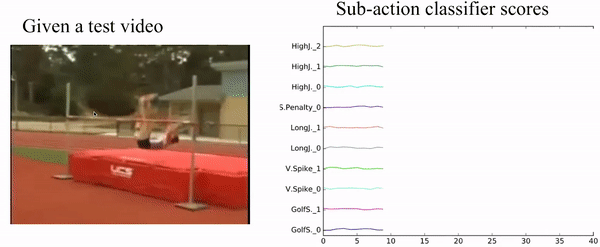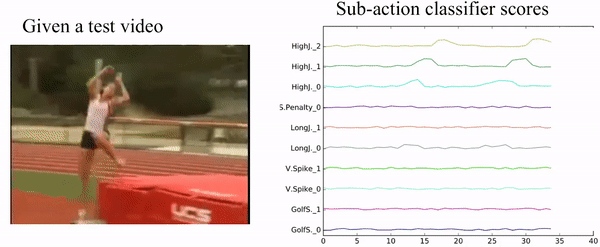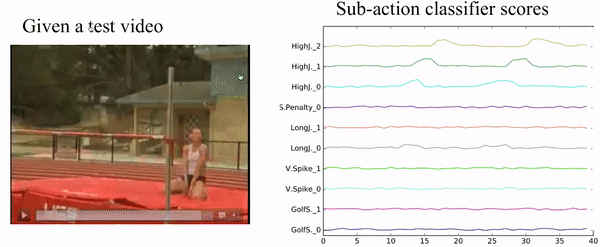
Fig. 1, [19] A complex human activity usually is sub-divided into unit-actions.
An one-fits-all HCI solution extracts generic sub-actions that shared across dataset.
Deep Learning models are state-of-the-art for action recognition tasks but frequently treat the complex activities as the singular objectives and lack interpretability. Therefore, recent works started to tackle the problem of exploration of sub-actions in complex activities. In this article, we introduce a novel approach to explore the temporal structure of detected action instances by explicitly modeling sub-actions and benefit from them. To this end, we propose to learn sub-actions as latent concepts and explore sub-actions via Node Attention Module (NAM). The proposed method maps both visual and temporal representations to a latent space where the sub-actions are learned discriminatively in an end-to-end fashion. The result is a set of latent vectors that can be interpreted as cluster centers in the embedding space. NAM is highly modular and extendable. It can be easily combined with exist deep learning model for various other video-related tasks in the future.
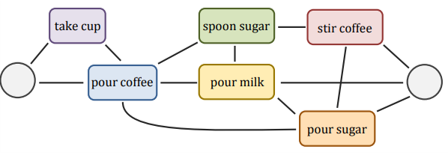
Fig. 2, [3] The activity of “preparing coffee” can be represented as undirected graph of unit-actions.
In recent years, deep learning has dominated many computer vision tasks, especially in action recognition, which is an important research filed to study almost all real-world videos contain multiple actions, and each action is composed of several sub-actions. As shown in Fig.2, [3, 17, 14], for instance, the activity of “preparing coffee” can be represented as undirected graph of unit-actions, include “take cup”, “pour coffee”, “pour sugar” and “stir coffee”.

Fig. 3, [17] In the video of a basketball game, shooting and blocking events must occur near-by.
Furthermore, detecting the frames of one activity in the video should benefit from information in the frames corresponding to another activity. As shown in Fig.3, a block event cannot occur without a shot event.

Fig. 4, [16] Different action instances can share similar motion patterns.
By the same token, a complex action is inherently the temporal composition of sub-actions, which means sub-actions may have contextual relations, or in other words, sub-actions of the same action should simultaneously appear in the corresponding video. As shown in Fig.4, e.g., the “jump” sub-action in the red box will always appear in its intra-class instances, and also be shared across several action as well.
Action recognition is the problem of identifying events performed by humans given a video input, there are two primary challenges:
Many high-level activities are often composed of multiple temporal parts with different duration/speed.
–> Implicitly modeling sub-action to preserve essential properties
Usually given video- /frame- level category labels, the sub-actions are undefined and not annotated.
–> Represent video features via a group of sub-actions, i.e., the sub-action family.
We would like to perform frame-wise inference. Existing approaches try to explore sub-actions from a given video frame [17, 14], or given video segments [15, 12]. Among them, those approaches using video segments as input need to rely on multiple timestamp inputs to extract features, which means that several timestamp information must be considered as input to capture context from adjacent frames.
Learning to represent videos is important. It requires embedding spatial and temporal information in a series of frames. Convolutional Neural Network (CNN) followed with a Recurrent Neural Network (RNN) is a backbone network widely used to extract spatiotemporal information. In the past few years, some research tend to extract spatiotemporal information through 3D convolutional networks have gradually received a great amount of attention, such as I3D [18]. In this article, we tend to use recursive-based methods (such as CNN with RNN) instead of 3D convolutional networks since consideration of the efficiency of real-time per-frame inference and the model size.
Node Attention Learning
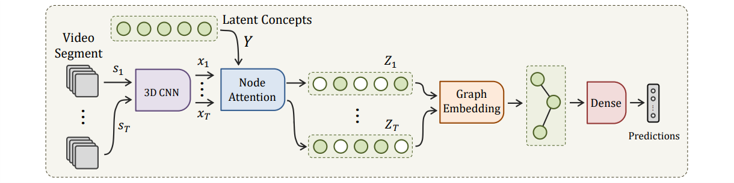
Fig. 5, [3].
Inspired by [3], in a dataset of human activities, unit-actions can be thought of as the dominant latent short-range concepts. That is, unit-actions are the building blocks of the human activity. As shown in Fig.5, in order to the associating sub-actions across each actions, we introduce a set of vectors as a memory bank of sub-action templates, which then serve as our sub-action pool and will be projected to meaningful latent space, we called latent concepts.
There are three key points worth to be mentioned:
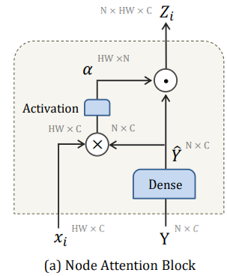
Fig. 6, [3] Node Attention Module.
Although the properties of this work meets our goal, there are some concerns. First of all, it can not perform frame-wise inference. Second, this model is hard to learn since it has asked to learn the relationship of each nodes by itself. To tackle it, we have made the following modifications: (1) the embedding network extracts per-frame deep features by using 2D CNN instead of 3D networks. (2) we borrow the way of learn relationship of each nodes from paper [12].
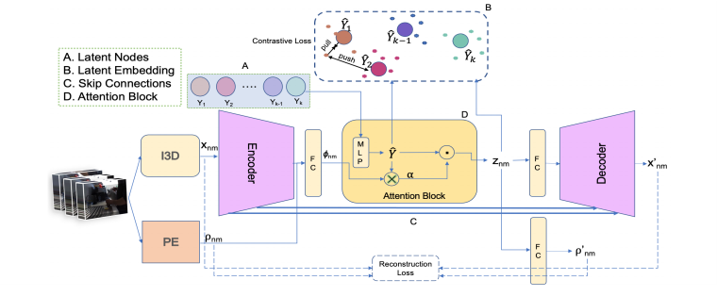
Fig. 7, [12] Unsupervised sub-action learning in complex activities.
As shown in Fig.7, [12]’s objective is to learn latent concepts which can be represented as the potential sub-actions. The similarity between the latent concepts of the same sub-action and the maximum confident input features is maximized, while the similarity w.r.t other input features is minimized.
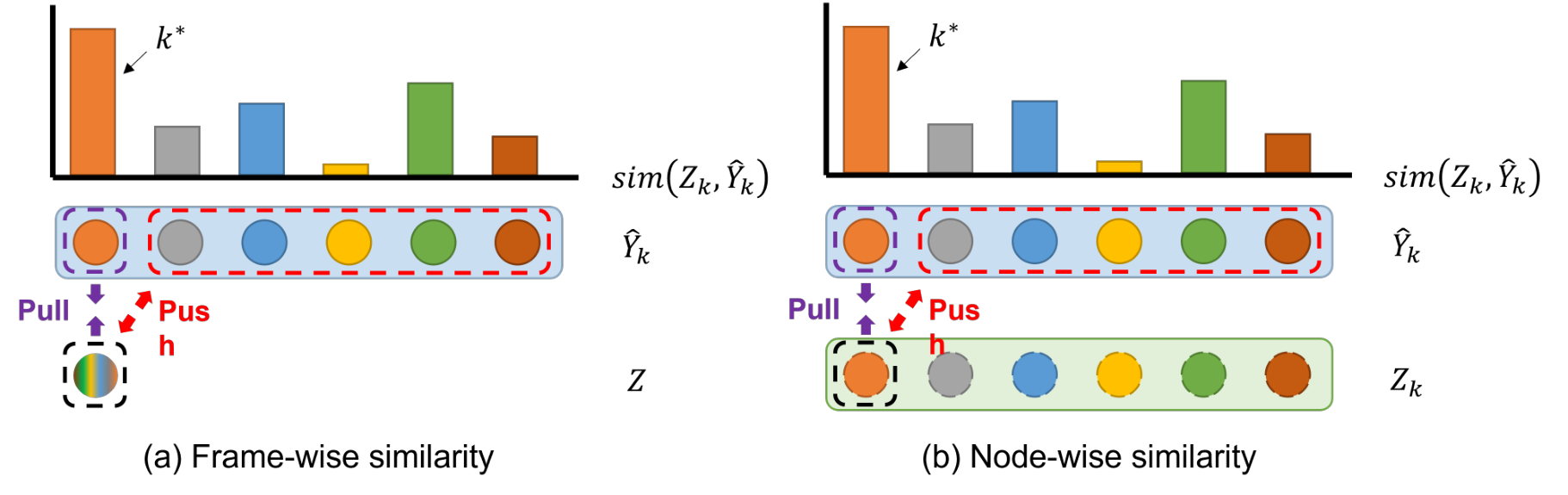
Fig. 8, Disentangle latent concept learning.
Different from [12], we only consider k-th self-similarity (Fig.8(b)) instead of summary of latent concepts (Fig.8(a)).
Additional Constraints
You might think that [3] has already dealt with both action and sub-actions detection task from the perspective of the graph theory, and we proposed an alternative way to improve the performance as well, why we still need plug and play? Indeed, [3] is a multi-task learning method, which significantly degrades the performance of action detection due to the dependency of sub-action family representations. That’s why we’ve positioned our approach to Plug and Play.
In our work, given a trained action detection model, we just simply freeze the weights and apply NAM to extract sub-actions. Which means that we tackle this problem in two stages, where during the first stage an embedding based on visual and temporal information is learned, and in the second stage clustering is applied on this embedding space.
We present a plug-and-play python module based on pytorch framework. An example of using our module is as follows.
def NodeAttentionModule(x):
# x: feature tensor, output of RNN backbone
# x’s size: (B, T, D)
# nodes: node tensor, must be initialized at beginning
# nodes’s size: (D, N)
# Q path
x = relu(bn(x))
x = fc_x(x)
# K path
n = relu(bn2(nodes))
n = fc_n(n)
# Q and K path
A = matmul(x, n)
A = softmax(A, dim=-1)
return A
Fig. 9, Visualization of our sub-action result.
First, our framework uses prototypes to represent sub-actions, which can be automatically learned in an end-to-end way. Second, the sub-action mechanism directly learns from individual videos and does not require triplet samples, which avoids the complicated sampling process. Besides, in the learning process, all videos interact with the same sub-action family, which provides a holistic solution to study all available videos. Moreover, the proposed method performs at the sub-action level and bridges videos from different categories together. We proposed a plug-and-play Node Exploration Module (NEM) to predicts the action units within an action in videos. To our knowledge, this is the first work exploring a plug-and-play module for sub-action representation learning, capturing temporal structure and relationships within an action.
[1] Cao, Kaidi, et al. Few-shot video classification via temporal alignment. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[2] Md Atiqur Rahman and Yang Wang. Optimizing intersection-over-union in deep neural networks for image segmentation. In Advances in Visual Computing, pages 234–244, Cham, 2016. Springer International Publishing.
[3] Noureldien Hussein, Efstratios Gavves, and Arnold W. M. Smeulders. Videograph: Recognizing minutes-long human activities in videos, 2019.
[4] Xinyu Li, Yanyi Zhang, Jianyu Zhang, Shuhong Chen, Ivan Marsic, Richard A. Farneth, and Randall S. Burd. Concurrent activity recognition with multimodal cnn-lstm structure, 2017.
[5] Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadar- rama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolu- tional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
[6] Gunnar A. Sigurdsson, Santosh Divvala, Ali Farhadi, and Abhinav Gupta. Asynchronous temporal fields for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[7] Huijuan Xu, Abir Das, and Kate Saenko. R-c3d: Region convolutional 3d network for temporal activity detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017.
[8] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotem- poral convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[9] Limin Wang Zhifeng Li Zhenzhi Wang, Ziteng Gao and Gangshan Wu. Boundary-aware cascade networks for temporal action segmentation. In Computer Vision – ECCV 2020, pages 34–51, Cham, 2020. Springer International Publishing. ISBN 978-3-030-58595-2.
[10] Ping Li, Qinghao Ye, Luming Zhang, Li Yuan, Xianghua Xu, and Ling Shao. Exploring global diverse atten- tion via pairwise temporal relation for video summariza- tion. Pattern Recognition, 111:107677, 2021. ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2020. 107677. URL https://www.sciencedirect.com/ science/article/pii/S0031320320304805.
[11] Wang Luo, Tianzhu Zhang, Wenfei Yang, Jingen Liu, Tao Mei, Feng Wu, and Yongdong Zhang. Action unit memory network for weakly supervised temporal action localiza- tion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9969–9979, June 2021.
[12] Sirnam Swetha, Hilde Kuehne, Yogesh S Rawat, and Mubarak Shah. Unsupervised discriminative embedding for sub-action learning in complex activities, 2021.
[13] Pilhyeon Lee, Jinglu Wang, Yan Lu, and H. Byun. Back- ground modeling via uncertainty estimation for weakly- supervised action localization. ArXiv, abs/2006.07006, 2020.
[14] AJ Piergiovanni and Michael S. Ryoo. Learning latent super-events to detect multiple activities in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[15] Fuchen Long, Ting Yao, Zhaofan Qiu, Xinmei Tian, Jiebo Luo, and Tao Mei. Gaussian temporal awareness networks for action localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
[16] Linjiang Huang, Yan Huang, Wanli Ouyang, and Liang Wang. Modeling sub-actions for weakly supervised tem- poral action localization. IEEE Transactions on Image Processing, 30:5154–5167, 2021. doi: 10.1109/TIP.2021. 3078324.
[17] A. J. Piergiovanni, Chenyou Fan, and Michael S. Ryoo. Learning latent subevents in activity videos using tem- poral attention filters. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, page 4247–4254. AAAI Press, 2017.
[18] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
[19] Hou, Rui, Rahul Sukthankar, and Mubarak Shah. Real-Time Temporal Action Localization in Untrimmed Videos by Sub-Action Discovery. BMVC. Vol. 2. 2017.
 You-Feng Wu
You-Feng Wu